In this project, we will use the data focused on 7 countries: Canada, France, Germany, Italy, Japan, United Kingdom and United States. There are four sources of data. For employment data, the source is International Labour Organization. “ILO modelled estimates database” ILOSTAT. https://ilostat.ilo.org/data/. The data is collected from the underlying household survey datasets (mostly labour force surveys) compiled by national statistical offices around the world.For employment data about legislations, the source is World Bank Group, “Women Business and the Law 2024”. https://wbl.worldbank.org/en/wbl. The data is updated based on feedback from respondents with expertise in laws on family, labor and violence against women. For employment data about income, the source is US Labor Force, “Median annual earnings by sex, race and Hispanic ethnicity”, https://www.dol.gov/agencies/wb/data/earnings/median-annual-sex-race-hispanic-ethnicity. The data is collected from U.S. Census Bureau. For health data, the source is United Health Organization. “THE GLOBAL HEALTH OBSERVATORY”, https://www.who.int/data/gho/data/indicators The data is mainly collected from civil registration and surveys. For education data, the source is United Nations Educational, Scientific and Cultural Organization,“SDG Global and Thematic Indicators” https://uis.unesco.org/bdds. The data is collected from the respond of UIS questionnaires by national state authorities, usually the ministry of education or the national statistical office. Finally, for population data, the source is United Nations, “World Population Prospects”, https://population.un.org/wpp/Download/Standard/MostUsed/. It is collected through civil registration and vital statistics (CRVS) systems, population censuses, population registers and household surveys.All of these data are in csv format and updated annually. One issue related to these data, like population data and education data, is that it includes the estimate of data in the future, so the time exceed the current year, 2024. Since we are only making an exploratory analysis, not an estimate or model, so we exclude these data and limit the time from 2000 to 2024.
2.2 Missing value analysis
Code
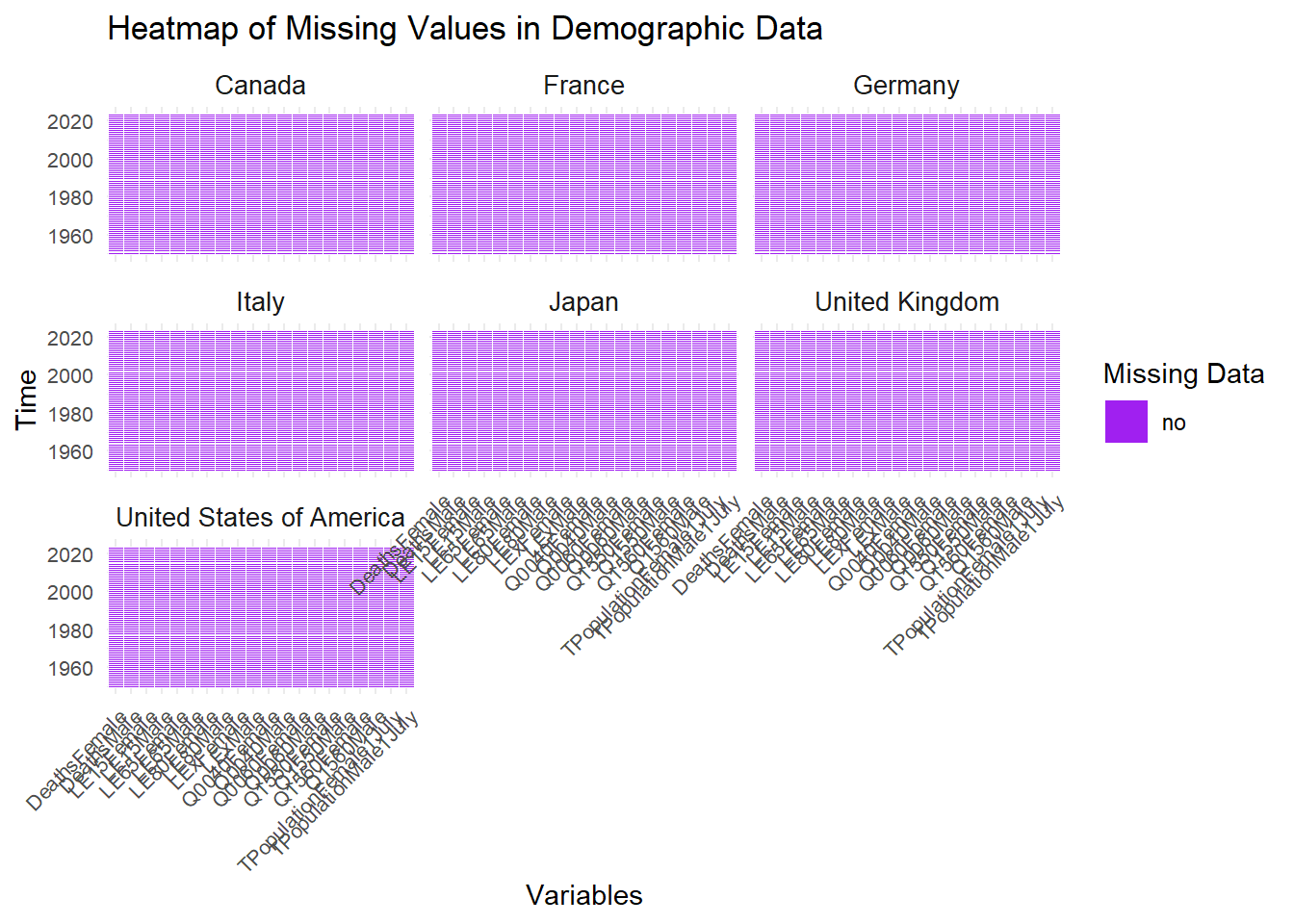
options(packageStartupMessage =FALSE)suppressMessages(library(tidyr))suppressMessages(library(dplyr))library(ggplot2)suppressWarnings(library(tidyverse))library(readr)# Data Source [United Nations]: https://population.un.org/wpp/Download/Standard/CSV/demographic_data <-read_csv("Demographic_data.csv",show_col_types =FALSE)# Select only G7 countries for downstream analysisG7_countries <-c("United States of America", "Canada", "United Kingdom", "France", "Germany", "Italy", "Japan")# Filter Conditions: historical data to 2023, columns with gender specificationg7_data_filtered <- demographic_data[ demographic_data$Location %in% G7_countries & demographic_data$Time <=2023, # c("Location", "Time", grep("Female", colnames(demographic_data), value =TRUE), grep("Male", colnames(demographic_data), value =TRUE))]invisible(colSums(is.na(g7_data_filtered)) |>sort(decreasing =TRUE))invisible(rowSums(is.na(g7_data_filtered)) |>sort(decreasing =TRUE))g7_data_filtered <- g7_data_filtered %>%mutate(across(-c(Location, Time), as.character))tidy_data <- g7_data_filtered |>pivot_longer(cols =-c(Location, Time), # Exclude "Location" and "Time" from pivotingnames_to ="Variable",values_to ="Value") |>mutate(Missing =ifelse(is.na(Value), "yes", "no")) ggplot(tidy_data, aes(x = Variable, y = Time, fill = Missing)) +geom_tile(color ="white") +scale_fill_manual(values =c("no"="purple", "yes"="yellow")) +labs(title ="Heatmap of Missing Values in Demographic Data",x ="Variables",y ="Time",fill ="Missing Data" ) +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1, size =8), axis.text.y =element_text(size =8), strip.text =element_text(size =10) ) +facet_wrap(~ Location)
Comment: This population dataset, sourced from the United Nations, was filtered to include G7 countries,Canada, France, Germany, Japan, Italy, the United Kingdom, and the United States, along with data from periods prior to 2023. We also selected gender-related variables to align with our research objectives. In ‘Heatmap of Missing Value in Demographic Data’, we found that there was no missing values, which indicated complete data with no need for data manipulation.
Code
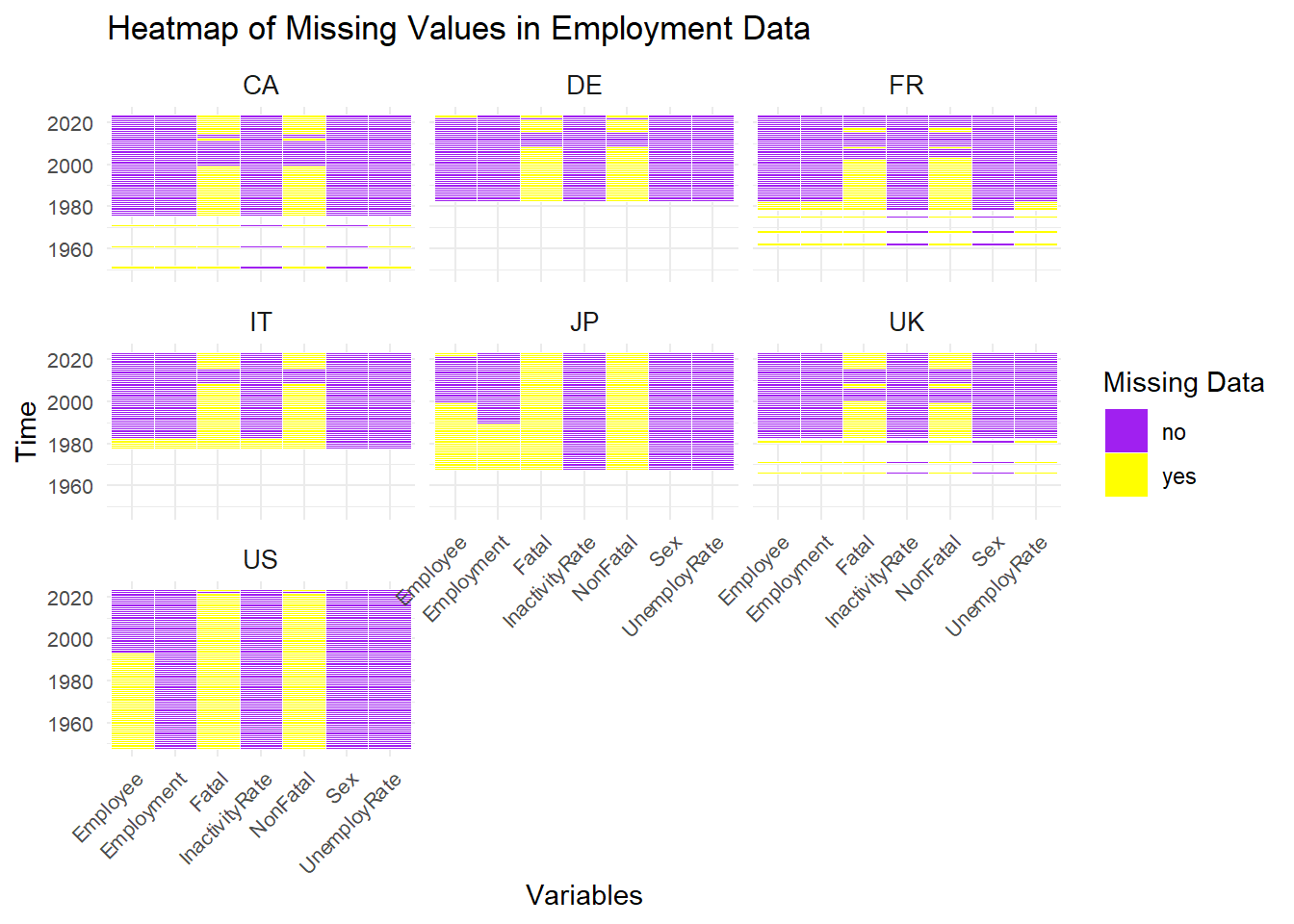
# Data Source [International Labour Organization]: https://ilostat.ilo.org/topics/sdg/##Unemployment by sex and age (thousands): Age is set to Aggregate Totalunemployment <-read_csv("Employment/UNE_TUNE_SEX_AGE_NB_A-filtered-2024-11-20.csv",show_col_types =FALSE)#SDG indicator 8.8.1 - Non-fatal occupational injuries per 100'000 workersnon_fatal <-read_csv("Employment/SDG_N881_SEX_MIG_RT_A-filtered-2024-11-20.csv",show_col_types =FALSE)#SDG indicator 8.8.1 - Fatal occupational injuries per 100'000 workersfatal <-read_csv("Employment/SDG_F881_SEX_MIG_RT_A-filtered-2024-11-20.csv",show_col_types =FALSE)#Inactivity rate by sex and age (%): Age is set to Aggregate Totalinactivity <-read_csv("Employment/EIP_DWAP_SEX_AGE_RT_A-filtered-2024-11-20.csv",show_col_types =FALSE)#Employment by sex and status in employment (thousands)employment <-read_csv("Employment/EMP_TEMP_SEX_STE_NB_A-filtered-2024-11-20.csv",show_col_types =FALSE)#Employees by sex and age (thousands): Age is set to Aggregate Totalemployee<-read_csv("Employment/EES_TEES_SEX_AGE_NB_A-filtered-2024-11-20.csv",show_col_types =FALSE)employee_filtered <- employee |>select(Location = ref_area.label,Sex = sex.label,Time = time,Employee = obs_value ) |>mutate(Sex =sub(".*: ", "", Sex) ) employment_filtered <- employment |>select(Location = ref_area.label,Sex = sex.label,Time = time,Employment = obs_value ) |>mutate(Sex =sub(".*: ", "", Sex) )fatal_filtered <- fatal |>select(Location = ref_area.label,Sex = sex.label,Time = time,Fatal = obs_value ) |>mutate(Sex =sub(".*: ", "", Sex) )non_fatal_filtered <- non_fatal |>select(Location = ref_area.label,Sex = sex.label,Time = time,NonFatal = obs_value ) |>mutate(Sex =sub(".*: ", "", Sex) )#Aggregate bands: Totalunemployment_filtered <- unemployment |>select(Location = ref_area.label,Sex = sex.label,Time = time,UnemployRate = obs_value ) |>mutate(Sex =sub(".*: ", "", Sex) )inactivity_filtered <- inactivity |>select(Location = ref_area.label,Sex = sex.label,Time = time,InactivityRate = obs_value ) |>mutate(Sex =sub(".*: ", "", Sex) )merged_data <- fatal_filtered |>full_join(non_fatal_filtered, by =c("Location", "Time", "Sex")) |>full_join(unemployment_filtered, by =c("Location", "Time", "Sex"))|>full_join(employment_filtered, by =c("Location", "Time", "Sex"))|>full_join(employee_filtered, by =c("Location", "Time", "Sex"))|>full_join(inactivity_filtered, by =c("Location", "Time", "Sex"))location_abbreviations <-c("Canada"="CA","United States of America"="US","United Kingdom of Great Britain and Northern Ireland"="UK","Germany"="DE","France"="FR","Italy"="IT","Japan"="JP")merged_data$Location <- location_abbreviations[merged_data$Location]merged_data <- merged_data %>%mutate(across(-c(Location, Time), as.character))tidy_merge <- merged_data |>pivot_longer(cols =-c(Location, Time), names_to ="Variable",values_to ="Value") |>mutate(Missing =ifelse(is.na(Value), "yes", "no"))ggplot(tidy_merge, aes(x = Variable, y = Time, fill = Missing)) +geom_tile(color ="white") +scale_fill_manual(values =c("no"="purple", "yes"="yellow")) +labs(title ="Heatmap of Missing Values in Employment Data",x ="Variables",y ="Time",fill ="Missing Data" ) +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1, size =8), axis.text.y =element_text(size =8), strip.text =element_text(size =10) ) +facet_wrap(~ Location)
Comment: This data was sourced from International Labour Organization to visualized the gender difference in employment topic. We retrieved 6 different dataset and combined into one after manipulation. In ‘Heatmap of Missing Value in Employment Data’, we found that time ranges for seven countries varied, missing values were more prominent in the earlier decade, and variables - Fatal and NonFatal- had much more missing values than others. Hence, for our downstream analysis, we may apply the methods like imputation and wisely pick a time range.
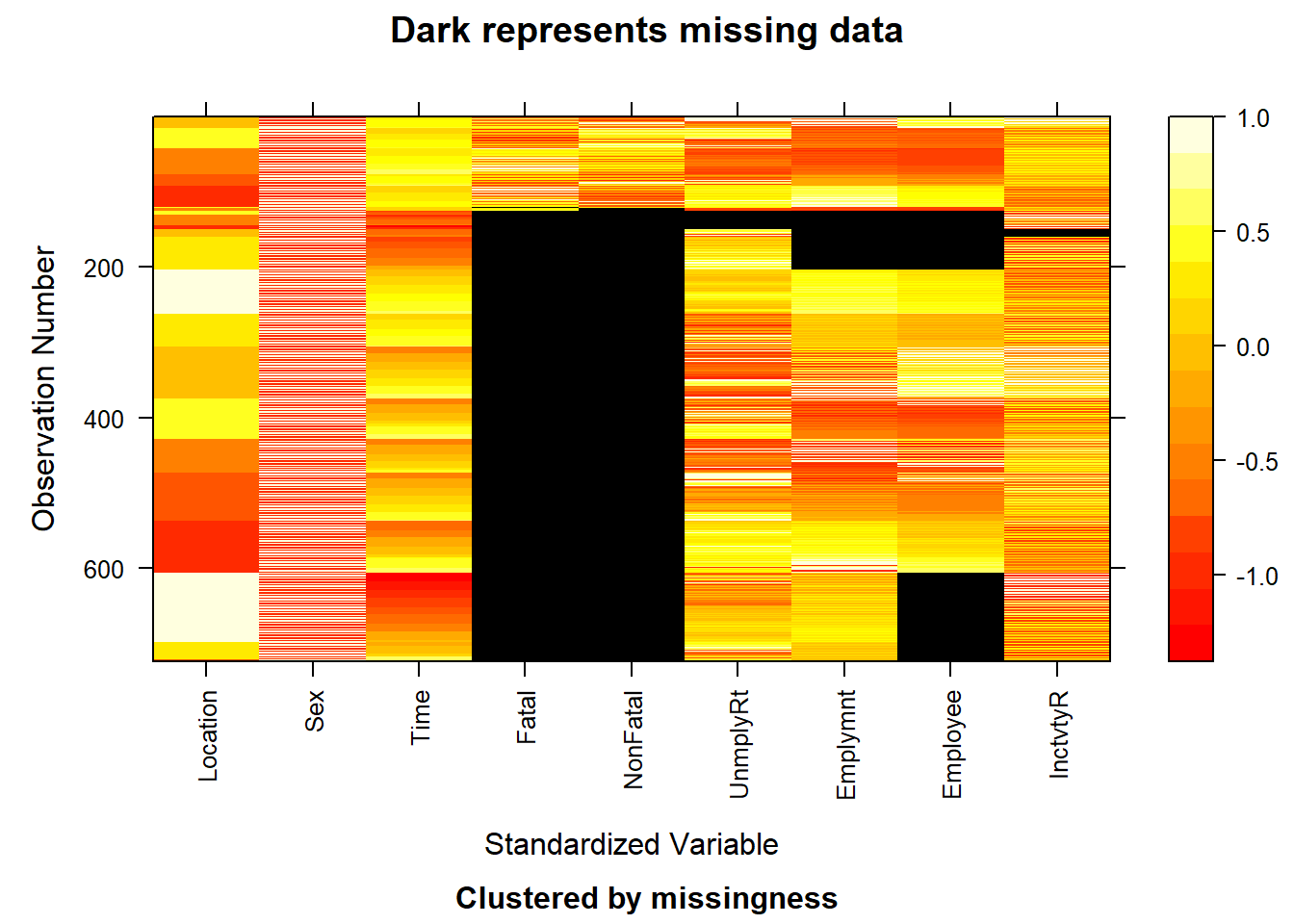
NOTE: In the following pairs of variables, the missingness pattern of the second is a subset of the first.
Please verify whether they are in fact logically distinct variables.
[,1] [,2]
[1,] "Fatal" "UnemployRate"
[2,] "Fatal" "Employment"
[3,] "Fatal" "Employee"
[4,] "Fatal" "InactivityRate"
[5,] "NonFatal" "UnemployRate"
[6,] "NonFatal" "Employment"
[7,] "NonFatal" "Employee"
[8,] "NonFatal" "InactivityRate"
[9,] "Employment" "InactivityRate"
[10,] "Employee" "InactivityRate"
Code
image(x)
Comment, combined with this Missing Data Heatmap, we can further ensure our thoughts that Fatal and NonFatal requires further manipulation. Otherwise, analyses focusing on earlier periods in regards to these two variables may face limitations due to incomplete data. Besides, missingness in other variables is not that prominent, but we need to figure out if it is random to avoid biases.